The following is an article I wrote based on a note I sent to the Mozilla Developer Network mailing list about an idea that crossed my mind to help scale a CMS driven website.
I’m convinced i am not the first one who came out with a similar idea, but I thought it would be useful to share anyway.
What’s common on a CMS driven Website?
What affects the page load is what happens in the backend before getting HTML back to the web browser. Sometimes its about converting the text stored in the database back into HTML, making some specific views, and the list can go on and on.
Problem is that we are spending a lot of CPU cycles to end up serving time and time again the same content, unique for each user when about 90% the generated content could be exactly the same for everybody.
with web apps is that we make backend servers generate HTML as if it was unique when, in truth, most of it could be cached.
What if we could make a separation between what’s common, and use caching and serve it to everybody.
How HTTP cache works, roughly
Regardless of what software does it: Squid, Varnish, NGINX, Zeus, caching is done the same way.
In the end, the HTTP caching layer basically keeps in RAM generated HTTP Response body and keeps in memory based on the headers it had when it passed it through to the original request. Only GET Responses, without cookies, are cacheable. Other response body coming from a [PUT, DELETE, POST] request aren’t.
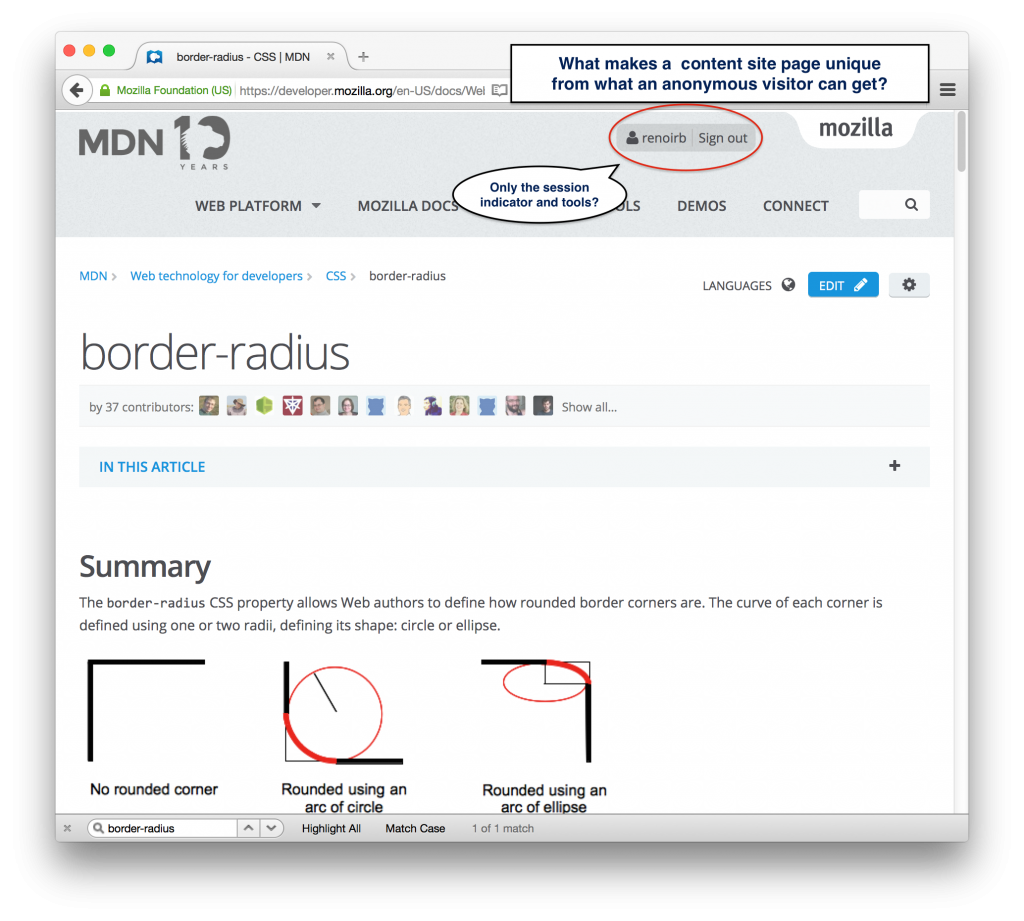
To come back on my previous example, what part is unique in the the current user compared to what the anonymous visitor gets on a documentation Website page.
What does a Website view serves us then? The content of the page, the “chrome” (what’s always there), Links to account settings, edit, or visualize details for the current page, account settings, the username, link to logout.
It means we are making unique content for things that could be cached and wasting cycles.
Even then, most of the content is cacheable because they would generally be with the same paths in the CMS.
How about we separate dynamic from static?
This makes me wonder if we could improve site resiliency by leveraging HTTP caching, strip off any cookies, and factor out what’s unique on a page so that we get the same output for any context.
As for the contextual parts of the site ‘chrome’, how about we expose a context-root which would take care of serving dynamically generated HTML to use as partials.
One way of doing it would be to make that context-root generate simple HTML strings that we can pass to a JavaScript manager that’ll convert it into DOM and inject it in the ‘chrome’.
Since we can make cookies to be isolated to specific context-roots, we can keep the statefulness of the session on MDN and have a clear separation of what’s dynamic and what’s not.